Présentation d´un script shell personnel permettant de mettre en place une sauvegarde de données grâce au fameux outil rsync, via Internet, sur un schéma de snapshots. Autrement dit, d’images des données à un instant précis. Le script permet la rotation des sauvegardes et une distribution non linéaire des plus anciennes.
Le contexte
Pour stocker mes précieuses données numériques personnelles j’utilise un NAS, basé sur FreeNAS, dont on a vu tout le processus de configuration dans les deux pages dédiées ici et là. Pour sauvegarder ces mêmes données dans un lieu physiquement séparé j’utilise un second NAS situé 500km plus loin. Entre les deux il y a … des lignes téléphoniques de particuliers, toutes simples, avec les limitations d’upload que cela implique : soit à peut près 100ko/s maximum.
Le système d’exploitation est FreeNAS, dérivé de FreeBSD, ce script est donc un script bash, il devrait tourner sans problème à priori sur tout système Unix, Linux et dérivés.
Le principe « snapshots-like », l’utilisation de liens en durs (on va en reparler), et la suppression partielle des anciennes sauvegardes sont inspirés des scripts et informations de François Scheurer, Mike Rubel et Michael Jakl.
Philosophie du script
Tous les possesseurs de Mac connaissent Time Machine, cet utilitaire de sauvegarde extrêmement bien conçu et à ma connaissance malheureusement sans équivalent sous Windows. Et bien en gros ce script de sauvegarde fonctionne de façon similaire, la jolie interface graphique en moins.
Le script crée quotidiennement une image des données sources sur la machine de destination, ainsi on a sur le NAS de sauvegarde un dossier par jour qui contient l´image complète de la source. Pour restaurer un fichier ou un dossier il suffit de choisir la date voulue et on retrouve toute l’arborescence telle qu’elle était à ce moment là. Les sauvegardes sont numérotées : 000 pour la plus récente puis 001 pour celle de la veille, 002 pour l’avant veille, etc…il y a donc une rotation quotidienne des plus anciennes en ajoutant 1 à tous les numéros de dossier. Le script maintient également un dossier « courante » qui est en fait un lien symbolique vers le dossier de la dernière sauvegarde valide.
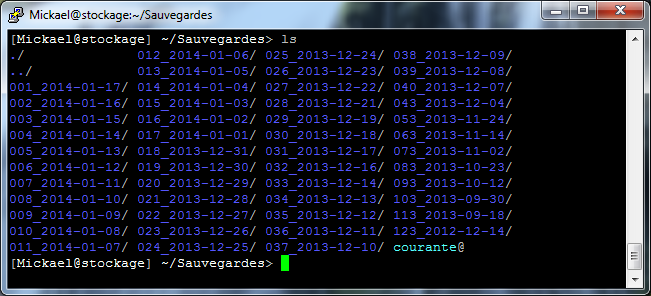 Après un certain temps, avoir une sauvegarde par jour ne sert plus à grand chose, l’idée est donc de supprimer quelques une des plus anciennes sauvegardes en partant du principe que plus elle sont anciennes et moins on a de chance d’en avoir besoin. Donc plus ça va et plus on les espace : une tous les 10 jours, puis 30 jours, etc…
Après un certain temps, avoir une sauvegarde par jour ne sert plus à grand chose, l’idée est donc de supprimer quelques une des plus anciennes sauvegardes en partant du principe que plus elle sont anciennes et moins on a de chance d’en avoir besoin. Donc plus ça va et plus on les espace : une tous les 10 jours, puis 30 jours, etc…
Le fonctionnement en détail
Structure générale
Je vous ai dit que l’on faisait une image des données sources par jour, alors évidemment on ne va pas transférer l’ensemble des données tous les jours. Rsync dispose d’une option magique (–link-dest= »reference ») qui compare les fichiers du dossier source avec le dossier « reference », si l’un est manquant il l’envoi dans la destination mais si le fichier existe dans la référence alors il créé simplement un lien en dur dans la destination vers celui ci. Ainsi pas de transfert de tout ce qui existe déjà !
Sauf que, problème ! Si un utilisateur renomme son dossier « Images » en « Photos », rsync ne le reconnaît pas dans le dossier de reference et on aura peut être 100, 300, 500Go ou plus à renvoyer vers la destination… à 100ko/s je vous laisse faire le calcul. :(Pour éviter ce problème de fichiers ou dossiers renommés, lié à la distance entre les NAS il existe un petit patch qui ajoute à rsync l’option –detect-renamed. –detect-renamed permet donc de repérer et d’éviter cela en utilisant simplement les données déjà à destination pour faire l’image du jour. Du coup je n’utilise pas l’option –link-dest.
Comme finalement on n’utilisera pas l’option link-dest, afin d’avoir les liens en durs vers les fichiers préexistant on va donc commencer par faire une copie complète avec des liens puis on mettra celle-ci à jour. Pour fonctionner correctement en cas de renommage de dossier ou de déplacement de fichier dans la source vers un nouveau dossier, detect-renamed doit avoir dans la destination l’arborescence identique à la source.
Si j’ajoute un contrôle d’unicité au lancement afin de ne pas se retrouver avec 2 scripts qui font la même chose en parallèle, ce qui collerai un gros bazar, ainsi qu’un retour d’erreur par mail à a fin, on obtient en gros cette structure :
# # Y'a t'il un script précédent encore lancé ? # -> si oui on le supprime # #Copie en liens durs de la sauvegarde "courante" vers le dossier 000 #Mise à jour de l'arborescence de la destination à partir de la source # -> si erreur dans la mise à jour, on stoppe, envoi mail #Transfert des fichiers modifiés # -> si erreur dans le transfert, on stoppe, envoi mail # #Si tout c'est bien terminé on effectue la rotation : 000 devient 001, 001->002, etc... #Création du lien pour dire que la nouvelle sauvegarde courante est la 001 #Suppression sélective de certaines sauvegardes anciennes #Envoi de mail et enregistrement du log #
A cela s’ajoute la contrainte du débit en upload limité, du coup en cas de gros volume à transférer il se pourrait qu’au bout de 24h la sauvegarde de la veille ne soit pas terminée. Pour traiter ce cas on ajoute un suffixe _incomplete au nom de dossier et on utilise cette sauvegarde comme nouvelle référence pour la suivante, ainsi le travail effectué n’est pas perdu. Le suffixe permettra à la fonction de suppression de ne pas garder la sauvegarde longtemps car elle n’a pas d’interêt.
De plus comme l’upload est limité et toujours en cas de gros volume il peut être contraignant de saturer la ligne téléphone avec la sauvegarde. J’utilise donc un autre patch de rsync : –stop-at. Il permet d’indiquer à rsync de se fermer à une heure prévue. Ainsi de minuit à 8h j’upload presque sans limitation, à 8h rsync se ferme, le script le détecte et relance une instance de rsync avec un débit limité à 50% environ jusqu’à 23h50.
Contrôle de l’unicité
Au lancement, le script créé un fichier « flag » qui sert à enregistrer les différents retours texte en cas de succès ou d’échec. A la fin, ce fichier est copié dans les logs puis supprimé. Le script teste donc si un fichier flag est déjà présent, trahissant ainsi soit une autre instance de script, soit un plantage ou arrêt système ayant empêché le script précédent de se terminer correctement. Dans le premier cas on ferme le rsync précédent, dans le second on supprime la sauvegarde précédente partiellement échouée et on reprend sur des bases saines.
Ceci est géré par cette partie du script :
#Si il y a déjà un fichier flag (anormal)=> la synchro de la veille n'est soit pas terminée (mauvaise programmation heure de fin) ou stoppée due à plantage ou arrêt système) if [ -e $flag ]; then pkill -SIGUSR1 -f -u $USER_CIBLE rsync #tente de fermer Rsync avec le signal SIGUSR1 (le signal est testé par le script de la veille et lui signal de se fermer également) sleep 120 #Tempo 120 secondes if [ -e $flag ]; then #Re-teste présence fichier flag. Si oui c'est que le script précédent n etait plus lance => il y a eu plantage ou arret de la machine l hébergeant date_veille=$(head -n 1 $flag | cut -c15-) #récupère la date sauvegarde interrompue (dans 1ere ligne du fichier flag) echo -e '\n!!!!!!!!!!\nScript du' $(date +%Y-%m-%d) >> $flag echo -e 'Suppression du dossier : 000_'$date_veille >> $flag rm -r $CIBLE/000_$date_veille >> $flag 2>&1 #supprime le dossier 000_ dans lequel la précédente sauvegarde a echoue envoi_mail 2 #mail sauvegarde non terminée cause arrêt NAS ou plantage script mv $flag $DOSS_SCRIPT/log/$date_veille-erreur$EXTENSION #déplace le fichier de flag dans le dossier des logs et le renomme fi fi
Transfert des fichiers, analyse du code retour
Pour s’assurer du bon déroulement des étapes critiques de la sauvegarde, à chaque exécution de rsync le code de retour est analysé. Parmis les codes remarquables citons :
- 0 : code signalant que rsync s’est terminé normalement
- 30 : signalant un arrêt sur timeout => peut être généré par l’option –stop-at, donc on s’en servira pour traiter le cas de l’arrêt programmé à heure fixée
- 19 : signale un arrêt suite à reception du signal SIGUSER1. C’est ce signal que l’on envoi avec la commande pkill (voir l’extrait de code ci-dessus) si l’instance précédente n’est pas fermée. Le script précédent peut ainsi savoir qu’un nouveau est lancé.
Mise en place et paramétrage du script
Script complet
Voici le script au complet, j’ai essayé de largement commenter le tout, cela sera bien plus lisible en le collant dans un éditeur comme Notepad++ ou autre.
NOTE : Mise à jour du script le 14 octobre 2014 avec une correction d’un bug au niveau du dossier des transferts partiels
#!/bin/bash
# Version 3.2 - sauvegarde_nuit
#
#Update depuis 3.1 :
# - déplacement "tempRsync" (dossier des incomplets) hors arborescence sauvegardée pour le préserver du --delete-excluded
# - suppression du dossier "tempRsync" en cas d'erreur lors de la synchro. Non touché en cas d'erreur autre (ex : connexion impossible)
# - amélioration test après une fin par time-out pour mieux détecter un run-time terminé (sort souvent en 3eme ligne avant
#fin de fichier mais parfois en 2ème ligne, donc ajout d'un "ou" dans le test
# - Suppression de l'option de compression -z (compression désormait assurée au niveau de ssh)
#
#-------------------------------------------------------------------------------------------------------------------------------------------#
# SYNCHRONISATION DISTANTE DES DONNES PAR RSYNC ENTRE 2 NAS #
# #
#Créé un fichier "flag", témoin de son lancement, puis démarre une sauvegarde miroir depuis une machine distante vers celle qui l'héberge #
#Lors du démarrage, il contrôle la présence du fichier flag, si celui ci est présent c'est qu'une synchro rsync est déjà en cours, #
#on la stoppe avec le signal SIGUSR1 (code retour 19 de rsync). Ceci fermera également le script qui l'a lancé #
# #
#Le script lance ensuite un "dry run" pour tester la connexion et lister le volume de données à envoyer. Les stats sont envoyées dans le #
#fichier de flag. Si tout s'est bien passé on lance la synchronisation réelle : d'abord mise à jour des dossiers puis des fichiers #
# #
#En cas d'erreur de rsync ou de sauvegarde de la veille non terminée, on envoie un mail pour alerter l'administrateur #
#En cas de bonne exécution, le fichier flag est transformé en fichier log dans le dossier de la sauvegarde #
# #
#Le script utilise une version patchée de rsync incluant les options --detect-renamed pour ne pas retransférer des fichiers renommés ou #
#déplacés et --stop-at pour donner une heure d'arrêt de rsync. La version patchée de rsync doit être installée sur les 2 machines #
#-------------------------------------------------------------------------------------------------------------------------------------------#
#VARIABLES ET CONFIGURATION
#**********************************************************************************
#Configuration :
LIMITATION_JOUR=1 #Mettre à 1 pour activer une limitation de la bande passante différente en journée, 0 = pas de différence
DEBUT_JOUR="08:00" #Heure de début de limitation pour le jour, format hh:mm impératif
BP_LIMITE_JOUR=60 #Bande passante maximale en ko/s. 0 = pas de limite
FIN_SAUVEGARDE="23:50" #Heure de fin de la sauvegarde, format hh:mm (avant l'heure de début de la suivante)
BP_LIMITE=100 #Bande passante maximale en ko/s. 0 = pas de limite
MAIL_SUCCES=0 #Mettre à 0 pour ne pas recevoir le rapport de sauvegarde par mail en cas de succès. Aucune influence sur les rapports d'erreur
DOSS_SCRIPT="/mnt/pool_sauvegarde/Scripts" #Dossier abritant ce script
NOM_FLAG="flag" #Nom du fichier "flag" (sans extension)
EXTENSION=".log" #Extension à ajouter aux fichiers logs générés
DOSSIER_SOURCE="/mnt/Tank/" #Dossier source à sauvegarder
NAS_DISTANT=xxx.xxx.xxx.xxx #Adresse du serveur source
PORT=22 #Port du service ssh serveur source
USER="User" #Nom d'utilisateur source
USER_MAIL="user@monmail.com" #E-mail pour la reception des rapports
CIBLE="/mnt/pool_sauvegarde/Sauvegardes" #Dossier de destination des sauvegardes (un dossier par date est créé ensuite à l'intérieur)
USER_CIBLE="UserSauvegarde" #Nom d'utilisateur serveur destination
EXCLUS="/mnt/pool_sauvegarde/Scripts/liste.txt" #Liste des fichiers et dossiers à exclure de la sauvegarde
#FIN DES VARIABLES ET DE LA CONFIGURATION, NE PAS MODIFIER PLUS BAS
#*******************************************************************************************************************************************
# La fonction envoi_mail gère l'ajout des textes explicatifs et l'envoi des mails aux utilisateurs
#
#Le mail envoyé dépend de l'argument passé à cette fonction :
# 1 = Synchro précédente non terminée
# 2 = Fin anormale de la synchro précédente (plantage script ou panne électrique)
# 3 = Erreur lors du premier rsync d'analyse
# 4 = Erreur lors du rsync de sauvegarde
# 5 = Erreur lors du rsync de mise à jour arborescence
# 6 = Le script a ete stoppé par une nouvelle occurence du script => mauvaise programmation des heures
#
# 9 = Sauvegarde terminée avec succès
#--------------------------------------------------------------------------------------------------------------------
function envoi_mail()
{
if [ $1 -eq 1 ]; then
echo -e '\n*** ATTENTION ! ***' >> $flag
echo -e 'cette sauvegarde distante n a pas pu être complétée dans les dernières 24h\n' >> $flag
echo -e 'aide :' >> $flag
echo -e 'number of files = nombre total de fichiers dans la source' >> $flag
echo -e 'number of files transferred = nombre de fichiers qu il y avait à envoyer : absent -ou modifiés- de la destination' >> $flag
echo -e 'total transferred size = Volume des données qu il y avait à envoyer\n' >> $flag
mail -s 'NAS Caution: Sauvegarde distante non terminée' $USER_MAIL < $flag
elif [ $1 -eq 2 ]; then
echo -e '\n*** ATTENTION ! ***' >> $flag
echo -e 'cette sauvegarde distante n a pas été terminée correctement' >> $flag
echo -e 'Cela peut être du à un arrêt du NAS cible (hebergeant le script et les sauvegardes), une panne électrique ou un plantage du script\n' >> $flag
echo -e 'aide :' >> $flag
echo -e 'number of files = nombre total de fichiers dans la source' >> $flag
echo -e 'number of files transferred = nombre de fichiers qu il y avait à envoyer : absent -ou modifiés- de la destination' >> $flag
echo -e 'total transferred size = Volume des données qu il y avait à envoyer\n' >> $flag
mail -s 'NAS Caution: Sauvegarde distante interrompue' $USER_MAIL < $flag
elif [ $1 -eq 3 ]; then
echo -e '\n ==> ERREUR RSYNC LORS DU DRY-RUN, ARRET DU SCRIPT, erreur Rsync n°'$retval >>$flag
mail -s 'NAS Warning : ECHEC DE SAUVEGARDE DISTANTE LORS DE L ANALYSE' $USER_MAIL <$flag
elif [ $1 -eq 4 ]; then
echo -e '\n ==> ERREUR RSYNC LORS DE LA SYNCHRO, ARRET DU SCRIPT. Erreur n°'$retval >> $flag
mail -s 'NAS Warning : ECHEC DE SAUVEGARDE DISTANTE' $USER_MAIL <$flag
elif [ $1 -eq 5 ]; then
echo -e '\n ==> ERREUR RSYNC LORS DE LA MISE A JOUR DE L ARBORESCENCE, ARRET DU SCRIPT. Erreur n°'$retval >> $flag
mail -s 'NAS Warning : ECHEC DE SAUVEGARDE DISTANTE' $USER_MAIL <$flag
elif [ $1 -eq 6 ]; then
echo -e '\n*** ATTENTION ! ***' >> $flag
echo -e 'Cette sauvegarde a été interrompue suite au demarrage d une autre sauvegarde' >> $flag
echo -e 'VERIFIEZ LA CONFIGURATION DE L HEURE DE FIN QUI DOIT ETRE PROGRAMMEE AVANT LE DEBUT DE LA SUIVANTE' >> $flag
mail -s 'NAS Warning : ECHEC SAUVEGARDE, VERIFIEZ LA PROGRAMMATION' $USER_MAIL <$flag
elif [ $1 -eq 9 ]; then
if [ $MAIL_SUCCES -ne 0 ]; then #Envoie le mail si MAIL_SUCCES n'est pas 0 dans la conf
echo 'Sauvegarde terminée avec succès' >> $flag
mail -s 'NAS : Sauvegarde distante réussie' $USER_MAIL <$flag
fi
fi
}
# La fonction copie_liens permet de créer au début de la sauvegarde l'image précedente en faisant une copie de la
#sauvegarde N-1 par des liens en durs, cette copie sera ensuite exploitée par rsync pour la mettre à jour.
# L'utilisation de ce système à la place de l'option --link-dest de rsync permet d'utiliser l'option --detect-renamed de
#rsync
#----------------------------------------------------------------------------------------------------------------------
function copie_liens()
{
cp -alL $CIBLE/courante $CIBLE/000_$date_jour 2>> $flag #copie (liens durs) de la sauvegarde courante. Sert de base et est mise à jour ensuite
echo -e '\nCopie image courante terminée...' >> $flag
}
# La fonction lien_courante permet de mettre à jour le lien symbolique "courante" sur la sauvegarde distante
# qui pointe vers la sauvegarde actuelle (c'est l'image courante)
# La fonction reçoit un argument qui est le dossier à lier au dossier "courante"
#----------------------------------------------------------------------------------------------------------------------
function lien_courante()
{
rm -rf $CIBLE/courante 2>> $flag #Suppression du dossier de la sauvegarde courante...
ln -s $CIBLE/$1 $CIBLE/courante 2>> $flag #... et recréation (en fait un simple lien vers la sauvegarde du jour)
}
# La fonction rotation_sauvegardes permet d'incrémenter le numéro des dossiers contenant les sauvegardes en conservant la date, par
# exemple : 005_2012-12-12 est renommé en 006_2012-12-12. La sauvegarde numero 999 est supprimée.
# Cette fonction supprime également les sauvegardes incompletes (nom de dossier se terminant par _incomplete) à partir de la 25eme sauvegarde
#----------------------------------------------------------------------------------------------------------------------
function rotation_sauvegarde()
{
if ls $CIBLE/999_* > /dev/null 2>&1; then #suppression de la sauvegarde numéro 999 si elle existe
echo "suppression de la sauvegarde 999" >> $flag
rm -rf $CIBLE/999_* 2>> $flag
fi
for i in {999..0} #boucle de 999 à 0
do
ichaine=$(printf "%.3d" $i) #génère le numéro de sauvegarde sur 3 chiffres
if [ $i -gt 25 ] && find $CIBLE/${ichaine}_*_incomplete -maxdepth 0 > /dev/null 2>&1; then #à partir de la 25eme sauvegarde (et après) on teste si c'est une incomplète
echo "suppression de la sauvegarde incomplète ${ichaine}" >> $flag
rm -r $CIBLE/${ichaine}_*_incomplete 2>> $flag #si c'est une incomplète, on la supprime
fi
if ls $CIBLE/${ichaine}_* > /dev/null 2>&1; then #test de l'existence de la sauvegarde n
for k in $CIBLE/${ichaine}_*; do #si existe on récupère son nom complet (avec chemin et date)
let j=$i+1 #génére le numéro n+1 sur 3 chiffres
j=$(printf "%.3d" $j)
k=${k#${CIBLE}/} #supprime la partie chemin du nom de sauvegarde
mv $CIBLE/$k $CIBLE/${j}${k#$ichaine} 2>> $flag #renomme la sauvegarde n en n+1
done
fi
done
}
# La fonction suppression sauvegarde permet de supprimer les anciennes sauvegardes en en gardant 1 seule par interval défini. Elle reçoit
# 3 paramètres : une butée haute, une butée basse et un interval (dans cet ordre). La série entre les deux butées est divisées en intervals
# de la longueur définie par le paramètre interval puis une seule sauvegarde est conservée dans celui ci.
#Note : si la longueur de la série entre les butées n'est pas divisible par l'interval, le reste ne correspondant pas à un interval complet est
#ignoré (ex : de 100 à 75 par pas de 10 : on garde une sauvegarde entre 100 et 91, une entre 90 et 81 mais rien n'est supprimé entre 80 et 75
#-----------------------------------------------------------------------------------------------------------------------------------------------
function suppression_sauvegardes()
{
let start=$1 # initialise la première boucle avec la butée haute passée en paramètre
let stop=$start-$3+1 # initialise la première boucle avec le calcul de stop (start-pas+1)
let fin=$2 # récupère la butée basse en paramètre n°2
while [ $stop -ge $fin ] # Cette boucle génère les bornes entre les butées hautes, basses et avec l'interval passé en paramètre
do
f=0 #initialise le flag
for ((i=$start;i>=$stop;--i)) #boucle entre les bornes start - stop
do
ichaine=$(printf "%.3d" $i)
if ls $CIBLE/${ichaine}_* > /dev/null 2>&1; then #teste si on a une sauvegarde qui porte ce numéro
if [ $f -eq 0 ]; then #si on en a une on regarde si c'est la première
let f=1 #si oui, on positionne le flag pour dire qu'on en a une
else
k=$(find $CIBLE/${ichaine}_* -maxdepth 0)
echo "suppression de la sauvegarde "${k#${CIBLE}/} >> $flag #si ce n'est pas la première, on la supprime
rm -r $CIBLE/${k#${CIBLE}/} 2>> $flag
fi
fi
done
let start=$stop-1 #calculs prochaine bornes
let stop=$start-$3+1
done
}
#La fonction finalisation permet d'effectuer les dernières opérations communes à la fin de la sauvegarde normale :
#Ces opérations sont la rotation des sauvegardes puis la mise à jour du lien vers la sauvegarde courante et enfin la
#gestion de la suppression des plus anciennes sauvegardes selon une répartition spécifique et variable dans le temps
#-----------------------------------------------------------------------------------------------------------------------------------------------
function finalisation()
{
echo -e '\nSauvegarde terminée à '$(date +%H:%M:%S)'\nRotation des sauvegardes...' >> $flag
rotation_sauvegarde #Effectue le renommage de toutes les sauvegardes n en n+1 (rotation)
echo 'Rotation terminée, effacement et recréation du dossier de sauvegarde courante...' >> $flag
lien_courante 001_$date_jour #Suppression du dossier de la sauvegarde courante et recréation (en fait un simple lien vers la sauvegarde du jour)
suppression_sauvegardes 1000 401 200 #Suppression de quelques anciennes sauvegardes avec une répartition variable selon l'ancienneté
suppression_sauvegardes 400 131 30
suppression_sauvegardes 130 41 10
envoi_mail 9
mv $flag $DOSS_SCRIPT/log/$date_jour$EXTENSION #...déplace et renomme le fichier flag dans les logs
}
#La fonction finalisation_incomplete permet d'effectuer les dernières opérations communes à la fin d'une sauvegarde incomplete :
#renommage du dossier de sauvegarde avec ajout du suffixe "incomplete", rotation des sauvegardes puis la mise à jour du lien vers la sauvegarde courante
#-----------------------------------------------------------------------------------------------------------------------------------------------
function finalisation_incomplete()
{
echo -e '\nSauvegarde incomplete terminée à '$(date +%H:%M:%S)'\nRotation des sauvegardes...' >> $flag
mv $CIBLE/000_$date_jour $CIBLE/000_${date_jour}_incomplete
rotation_sauvegarde
echo 'Rotation terminée, effacement et recréation du dossier de sauvegarde courante...' >> $flag
lien_courante 001_${date_jour}_incomplete #Mise à jour de la sauvegarde courante
envoi_mail 1
mv $flag $DOSS_SCRIPT/log/$date_jour-incomplete$EXTENSION #déplacement fichier flag en log avec spécification incomplete
}
#La fonction finalisation_erreur permet d'effectuer les dernières opérations communes à la fin d'une sauvegarde qui se termine en erreur :
#renommage du dossier de sauvegarde avec ajout du suffixe "incomplete", rotation des sauvegardes puis la mise à jour du lien vers la sauvegarde courante
#-----------------------------------------------------------------------------------------------------------------------------------------------
function finalisation_erreur()
{
echo -e '\nErreur d execution à '$(date +%H:%M:%S)'\nSuppression du dossier 000_'$date_jour >> $flag
rm -r $CIBLE/000_$date_jour >> $flag 2>&1 #supprime le dossier 000 dans lequel on faisait la sauvegarde
if [ $1 -eq 4 ] && [ -e $DOSS_SCRIPT/tempRsync ]; then #si erreur lors de la synchro (1er argument = 4) on supprime aussi le dossier
echo -e '\nSuppression du dossier tempRsync' >> $flag #des incomplets rsync
rm -r $DOSS_SCRIPT/tempRsync
fi
envoi_mail $1 #envoi du mail selon le numéro d'erreur reçu en argument
mv $flag $DOSS_SCRIPT/log/$date_jour-erreur$EXTENSION #déplace le fichier de flag dans le dossier des logs et le renomme
}
#PROGRAMME PRINCIPAL, contrôle l'état actuel, prépare le dossier de sauvegarde, lance une analyse (dry-run rsync),
#puis copie l'arborescence des dossiers (sans supprimer les anciens) afin de permettre le bon fonctionnement de --detect-renamed
#en cas de fichiers déplacés ou dossiers renommés et enfin lance la sauvegarde effective des fichiers.
#Inclus le contrôle des codes retour des fonctions principales pour s'assurer de la bonne exécution.
#----------------------------------------------------------------------------------------------------------------------
flag=$DOSS_SCRIPT/$NOM_FLAG$EXTENSION #définition du fichier de flag
SOURCE=$USER@$NAS_DISTANT:$DOSSIER_SOURCE #et de la source
#Si il y a déjà un fichier flag (anormal)=> la synchro de la veille n'est soit pas terminée (mauvaise programmation heure de fin) ou stoppée due à plantage ou arrêt système)
if [ -e $flag ]; then
pkill -SIGUSR1 -f -u $USER_CIBLE rsync #tente de fermer Rsync avec le signal SIGUSR1 (le signal est testé par le script de la veille et lui signal de se fermer également)
sleep 120 #Tempo 120 secondes
if [ -e $flag ]; then #Re-teste présence fichier flag. Si oui c'est que le script précédent n etait plus lance => il y a eu plantage ou arret de la machine l hébergeant
date_veille=$(head -n 1 $flag | cut -c15-) #récupère la date sauvegarde interrompue (dans 1ere ligne du fichier flag)
echo -e '\n!!!!!!!!!!\nScript du' $(date +%Y-%m-%d) >> $flag
echo -e 'Suppression du dossier : 000_'$date_veille >> $flag
rm -r $CIBLE/000_$date_veille >> $flag 2>&1 #supprime le dossier 000_ dans lequel la précédente sauvegarde a echoue
envoi_mail 2 #mail sauvegarde non terminée cause arrêt NAS ou plantage script
mv $flag $DOSS_SCRIPT/log/$date_veille-erreur$EXTENSION #déplace le fichier de flag dans le dossier des logs et le renomme
fi
fi
date_jour=$(date +%Y-%m-%d) #Enregistrement date du jour
#Effacement et reCréation du fichier de flag :
echo 'SAUVEGARDE DU '$date_jour > $flag #NE PAS MODIFIER CETTE LIGNE
#Création du dossier de sauvegarde du jour : on recopie en liens l'image courante :
copie_liens
#on commence par un lancement de rsync en mode dry run pour lister dans le fichier de flag les fichiers à synchroniser (uniquement pour les statistiques)
echo -e 'Début analyse du volume à '$(date +%H:%M:%S) >> $flag
echo -e 'Rapport analyse, à synchroniser ce soir :\n----------------------------------------------' >> $flag
$DOSS_SCRIPT/rsync -ahzn -e "ssh -p "$PORT --stats --timeout=60 --delete --exclude-from=$EXCLUS $SOURCE $CIBLE/000_$date_jour >> $flag 2>&1
retval=$? #enregistre le code retour de rsync
if [ $retval -ne 0 ]; then #contrôle du code retour
#si erreur (clés ssh, connexion, serveur distant éteind, indisponible, ...) : on finalise et on quitte
finalisation_erreur 3
exit
fi
#Copie de l'arborescence des dossiers uniquement (ordre des option --includes/--exclude important, pas de --delete)
echo -e '\nDébut mise à jour arborescence à '$(date +%H:%M:%S) >> $flag
$DOSS_SCRIPT/rsync -ahz -e "ssh -p $PORT" --timeout=60 --exclude-from=$EXCLUS --include='*/' --exclude='*' $SOURCE $CIBLE/000_$date_jour >> $flag 2>&1
retval=$? #enregistre le code retour de rsync
if [ $retval -ne 0 ]; then #contrôle du code retour
#si erreur (clés ssh, connexion, serveur distant éteind, indisponible, ...) : on finalise et on quitte
finalisation_erreur 5
exit
fi
echo -e 'Mise à jour arborescence terminée à '$(date +%H:%M:%S) >> $flag
#Lancement de la synchro réelle :
if [ $LIMITATION_JOUR -ne 0 ]; then #Si débit different pour le jour on règle l'heure de fin en conséquence
heure_fin=$DEBUT_JOUR
else
heure_fin=$FIN_SAUVEGARDE
fi
echo -e '\n\nDébut de sauvegarde à '$(date +%H:%M:%S) >> $flag
echo -e 'Rapport de sauvegarde :\n----------------------------------------------' >> $flag
$DOSS_SCRIPT/rsync -ahz -e "ssh -p $PORT" --stats --delete --delete-excluded --detect-renamed --timeout=60 --bwlimit=$BP_LIMITE --stop-at=$heure_fin --partial --partial-dir="tempRsync" --exclude-from=$EXCLUS $SOURCE $CIBLE/000_$date_jour >> $flag 2>&1
retval=$? #enregistrement et contrôle du code retour
if [ $retval -eq 0 ]; then #si rsync est quitté normalement, terminé avant l'heure maxi, déroulement normal...
finalisation #on appelle la fonction de finalisation
exit
elif [ $retval -eq 19 ]; then #si rsync est quitté avec le code 19 (SIGUSR1) alors finalise et quitte le script car une nouvelle occurence s'est lancée...
finalisation_erreur 6
exit
elif [ $retval -eq 30 ]; then #si rsync est quitté avec un code 30 (timeout) on analyse si c'est l'heure de fin ou une autre erreur
if [ "$(tail -n -3 $flag | head -n 1)" = "run-time limit exceeded" ] || [ "$(tail -n -2 $flag | head -n 1)" = "run-time limit exceeded" ]; then #lecture 3ème ou 2ème ligne en partant de la fin de flag, si c'est bien une fin par run-time terminé et...
if [ $LIMITATION_JOUR -ne 0 ]; then #...Si on a programmé un débit different pour la suite
echo -e '\nFin de sauvegarde de nuit à '$(date +%H:%M:%S) >> $flag #on l'écrit et cela se poursuivra dessous
else #Sinon la sauvegarde est terminée et elle est incomplete
finalisation_incomplete #on finalise (renommage, rotation, lien courante)
exit
fi
else #si on a eu une erreur 30 mais que c'est inattendu, c'est un vrai timeout => erreur
finalisation_erreur 4
exit
fi
elif [ $retval -ne 0 ]; then #si on a une erreur autre, on finalise et on quitte
finalisation_erreur 4
exit
fi
#Lancement de la sauvegarde de jour si on a pas quitté le script au dessus
echo -e '\nDebut de la sauvegarde de jour' >> $flag
$DOSS_SCRIPT/rsync -ahz -e "ssh -p $PORT" --stats --delete --delete-excluded --detect-renamed --timeout=60 --bwlimit=$BP_LIMITE_JOUR --stop-at=$FIN_SAUVEGARDE --partial --partial-dir="tempRsync" --exclude-from=$EXCLUS $SOURCE $CIBLE/000_$date_jour >> $flag 2>&1
retval=$?
if [ $retval -eq 0 ]; then #si rsync est quitté normalement, terminé avant l'heure maxi, déroulement normal...
finalisation #on appelle la fonction de finalisation
exit
elif [ $retval -eq 19 ]; then #si rsync est quitté avec le code 19 (SIGUSR1) alors finalise et quitte le script car une nouvelle occurence s'est lancée...
finalisation_erreur 6
exit
elif [ $retval -eq 30 ]; then #si rsync est quitté avec un code 30 (timeout) on analyse si c'est l'heure de fin ou une autre erreur
if [ "$(tail -n -3 $flag | head -n 1)" = "run-time limit exceeded" ] || [ "$(tail -n -2 $flag | head -n 1)" = "run-time limit exceeded" ]; then #Si c'est bien l'heure de fin, c'est une incomplète
finalisation_incomplete #on finalise (renommage, rotation, lien courante)
exit
else #si on a eu une erreur 30 mais que c'est inattendu, c'est un vrai timeout => erreur
finalisation_erreur 4
fi
elif [ $retval -ne 0 ]; then #si on a une erreur autre, on finalise et on quitte
finalisation_erreur 4
exit
fi
Le script est prévu pour être exécuté via une tâche cron une seule fois par jour et ce sur la machine hébergeant les sauvegardes, cela me semblais plus robuste pour la création des liens, la rotation et suppression des sauvegarde en cas de coupure internet entre les machines.
Ici il est sur un pool dédié contenant 2 dossiers : Scripts et Sauvegardes. Script héberge le script et les logs, Sauvegardes, l’ensemble des sauvegardes. Bien sûr vous pouvez modifier tout cela dans les paramètres.
Version patchée de rsync
ATTENTION : le script en l’état utilise 2 options de rsync qui n’existent pas dans la version « officielle » actuelle. Il s´agit de –detect-renamed et de –stop-at dont on a parlé précédemment.
Pour inclure ces patches il est nécessaire de compiler rsync vous même en les incluant. Pour cela les sources se situent sur https://rsync.samba.org/ftp/rsync/ dans le dossier /src. Ou plus simplement dans les ports FreeBSD.
Pour ceux qui utilisent FreeNAS en version 64 bits, vous pouvez télécharger ma version ici même.
Paramétrage du script
L’ensemble des paramètres réglable est situé en tête du script (lignes surlignées en jaune ci-dessus) et sont normalement décrit. L’heure de fin est à mettre avant l’heure de début de la sauvegarde suivante (lancée par cron) pour un fonctionnement plus propre.
Ensuite évidemment il faut régler l’IP du serveur source, le nom d’utilisateur, le port et votre mail. Pour que tout fonctionne bien il faut avoir préalablement paramétré une authentification ssh par clé depuis le serveur distant hébergeant le script vers votre serveur local abritant les fichiers à sauvegarder. La connexion ssh doit avoir été ouverte au moins une fois pour ajouter la « key fingerprint » à la liste des serveurs connus.
La liste des exclus est un fichier contenant une liste des dossiers et des fichiers à ne pas envoyer vers la sauvegarde distante. Il suffit de faire précéder le nom des dossiers ou fichier par – pour les exclure comme sur cet exemple :
#
# Liste des dossiers / fichiers à exclure de la sauvegarde distante# Exclusion des dossiers
– Jail
– Plugins
– Medias
– Scripts
– Sauvegarde_MID/T??l??chargements
– Sauvegarde_MID/zip et exe*
– Sauvegarde_AD/T??l??chargements
– Sauvegarde_MD# Exclusion des fichiers et dossiers commençant par un point
#tels que .ssh et autres
– .*
ATTENTION : là encore un piège, il est indispensable d’avoir des sauts de ligne codés au format UNIX. Dans Notepad++ cela se fait avec Edition->Convertir les sauts de lignes.
Et voilà ! Normalement si tout ce passe bien vous allez recevoir un rapport quotidien (à condition d’avoir activé l’option). Celui ci contient les stats rsync du dry-run, s’exécutant donc AVANT l’envoi réel des fichier. Par conséquent quand on y lit « transfered file » il ne s’agit en fait pas des fichiers réellement transféré mais qu’il VA transférer. Si tout se termine en moins de 24h, c’est pareil, mais si vous avez trop de données à envoyer et que cela prend plus de 24h cela correspondra donc à ce qu’il reste à envoyer. Vous voyez la subtilité ?
N’hésitez pas à faire part de vos remarques ou suggestions, je suis preneur de tout ce qui peut l’améliorer car il n’est certainement pas parfait.




Bonjour,
Je trouve votre script super bien, par contre j’ai une difficulté, je ne sais pas comment on fait pour compiler rsync avec les options –detect-renamed et de –stop-at
Est ce que vous auriez un tuto ?
Pour infos je suis sur ubuntu.
Merci d’avance pour votre aide
Bonjour Olivier,
Merci pour le compliment. J’en ai profité pour mettre en ligne une petite mise à jour du script, pas grand chose mais j’avais apporté des modifs alors autant les partager.
Pour compiler sur Ubuntu c’est très simple : télécharge le code source de rsync (prend la dernière version tant qu’à faire !) et des patches associés à la version ici : https://rsync.samba.org/ftp/rsync/src/. Ce sont les fichiers .tar.gz
Ensuite tu les décompresses où tu veux pour avoir un dossier rsync-3.1.1 contenant les sources et également le dossier « patches » avec… les patches !
En ligne de commande, tu te met dans le dossier rsync et tu exécutes dans l’ordre:
patch -p1 < patches/time-limit.diff patch -p1 < patches/detect-renammed.diff ./configure make
Et voilà ! tu retrouves dans le dossier des sources l'exécutable "rsync" et si tu lances "./rsync --help" tu verras les nouvelles options dans la liste.
Pour finir tu peux remplacer les rsync d'origine dans /usr/bin/rync par cette version patchée comme ça c'est cette version qui s’exécutera en tapant simplement rsync
Bonjour Mickaël,
Merci beaucoup pour ta réponse et pour ton partage, je vais essayer ce week-end les infos que tu me donnes.
Pour infos j’utilise déjà le rsync pour sauvegarder les données de mon entreprise sur un serveur externe du mais ton code me semble tellement génial que j’ai hâte de le mettre en place.
Au passage encore félicitation pour ton travail, étant également codeur en PHP si je peux un jour t’apporter mon aide ce serait avec un très grand plaisir.
Cordialement,
Bonjour
Je suis nouveau sur Linux et je suis intéressé par votre script de sauvegarde.
Je suis sur Ubuntu 16.04.2LTS.
Or, j’ai lancé la procédure de compilation de rsync-3.1.2 avec les 2 patches. L’adjonction des 2 patches se passe bien, au détail près qu’il faut faire SUDO et qu’il y a une faute sur la 2ème commande « patch » : renamed ALD renammed.
Par contre, pour la dernière étape « ./configure make », impossible d’y parvenir…
Voici le message d’erreur obtenu :
nicolas@bureau:~/rsync-3.1.2$ sudo ./configure make
configure.sh: WARNING: you should use –build, –host, –target
configure.sh: Configuring rsync 3.1.2
checking build system type… Invalid configuration `make’: machine `make’ not recognized
configure.sh: error: /bin/bash ./config.sub make failed
nicolas@bureau:~/rsync-3.1.2$ ./rsync –help
bash: ./rsync: Aucun fichier ou dossier de ce type
Pouvez-vous m’aider à ce stade car l’esprit de votre script correspond exactement à ce que je recherche aujourd’hui ?
Merci d’avance,
Nicolas
Une idée comment patcher rsync sur Windows (Cygwin)